- Prerequisites.
- Building a cube.
Prerequisites
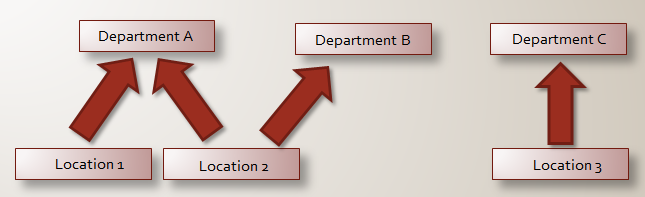
Below you can see a script i've been using for building a cube. At the end of the script i've added a couple of facts/events. So when we will quering this cube the following results should be shown for departments:
- Department A : 3
- Department B : 2
- Department C : 2
And for the locations:
- Location 1 : 1
- Location 2 : 2
- Location 3 : 2
First create a database and execute the following script:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[TestFact]') AND type in (N'U'))
DROP TABLE [dbo].[TestFact]
GO
CREATE TABLE [dbo].[TestFact](
[TestFactID] [int] IDENTITY(1,1) NOT NULL,
[FK_Date_Key] [int] NOT NULL,
[FK_Location_Key] [int] NOT NULL,
[TestFactCount] [int] NOT NULL
) ON [PRIMARY]
GO
----
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Location]') AND type in (N'U'))
DROP TABLE [dbo].[Location]
GO
CREATE TABLE [dbo].[Location](
[Location_Dim_key] [int] NOT NULL,
[Location_Code] [int] NOT NULL,
[Location_Description] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
----
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Department]') AND type in (N'U'))
DROP TABLE [dbo].[Department]
GO
CREATE TABLE [dbo].[Department](
[Department_Dim_key] [int] NOT NULL,
[Department_Code] [int] NOT NULL,
[Department_Description] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
---
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Bridge_Location_Department]') AND type in (N'U'))
DROP TABLE [dbo].[Bridge_Location_Department]
GO
CREATE TABLE [dbo].[Bridge_Location_Department]( [Bridge_Location_Department_ID] [int] IDENTITY(1,1) NOT NULL, [FK_Location_Key] [int] NOT NULL,
[FK_Department_Key] [int] NOT NULL,
[Valid_From] [date] NOT NULL,
[Valid_Until] [date] NOT NULL
) ON [PRIMARY]
GO
---
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[DimDate]') AND type in (N'U'))
DROP TABLE [dbo].[DimDate]
GO
CREATE TABLE [dbo].[DimDate](
[Date_dim_key] [int] NULL,
[Date_Year] [int] NULL
) ON [PRIMARY]
GO
---
INSERT INTO dbo.Department (Department_Dim_key, Department_Code, Department_Description)
VALUES (1, 1, ' Department A' ),(2, 2, ' Department B' ), (3, 3, ' Department C')
INSERT INTO dbo.Location (Location_Dim_key, Location_Code, Location_Description)
VALUES (1, 1, ' Location 1' ),(2, 2, ' Location 2' ), (3, 3, ' Location 3')
INSERT INTO dbo.Bridge_Location_Department (FK_Location_Key, FK_Department_Key, Valid_From, Valid_Until)
VALUES (1, 1, '2011-01-01', '9999-12-31' ),
(2, 1, '2005-01-01', '9999-12-31' ),
(2, 2, '2005-01-01', '9999-12-31' ),
(3, 3, '2005-01-01', '9999-12-31' )
INSERT INTO dbo.DimDate
VALUES (1,2000),
(2, 2001),
(3, 2002),
(4, 2003),
(5, 2004),
(6, 2005),
(7, 2006),
(8, 2007),
(9, 2008),
(10, 2009),
(11, 2010),
(12, 2011),
(13, 2012),
(14, 2013),
(15, 2014),
(16, 2015)
INSERT INTO [MultiValueDimension].[dbo].[TestFact]
([FK_Date_Key]
,[FK_Location_Key]
,[TestFactCount])
VALUES
(7, 1, 1),
(7, 2, 1),
(8, 3, 1),
(9, 3, 1),
(9, 2, 1)Building a cube
Okay, now we have to build a cube based on the tables created in SQL Server. Kimball calls this a multivalue dimension (actually it's a variant on the multivaluedimension, in my opinion). Microsoft calls this a many-to-many dimension (MM). Marc Russo published a great whitepaper on this subject. Many-to-many dimension (MM) is a better name for this subject. What can we say about Many-to Many dimension construction in relation to the case we are building:
- There are two measure groups needed.
- There are two dimnsions needed.
- The bridge Location Department table will be Intermediate Measure Group. The intermediate Measure Group is the measure group that relates the MM dimension to the regular dimension In this case it relates the location to the department dimension.
- Location is the intermediate dimension.

Designing this in the cube designer shows this picture:

So how does this looks in the dimension usage tab of the cube designer?

As said earlier in the post: location and department are the dimensions. Testfact and the bridge location department table are the measure groups. So when we check the results in the browser we see the following results for the locations:

And for the departments:

The total is still 5 but adding the departments subtotals manually is equal to 7!!!
And this is as predicted at the beginning of this post. So we have reached nirvana. Well not quite yet. What about history? What if a location do not exist anymore between departments and locations? What if locations shift from locations to other departments? You want to count your facts at right departments in a correct timeline! I'll blog about this in the future.
So, this is it for now.
Greetz,
Hennie










{kind=link}