For a while i collect MDX sample queries from different sources like the internet, books, etc for learning and implementing MDX queries. These are based on AdventureWorks 2008 R2. Sometimes, i had to rewrite the query because it was based on the Foodmart cube. So when you're learning MDX install the
adventureworks 2008 R2 databases. The analysis database need to be installed manually. Don't you forget this.
Ok here are the sample queries:
SELECT [Date].[Calendar Year].[CY 2005] on 0
FROM [Adventure Works];
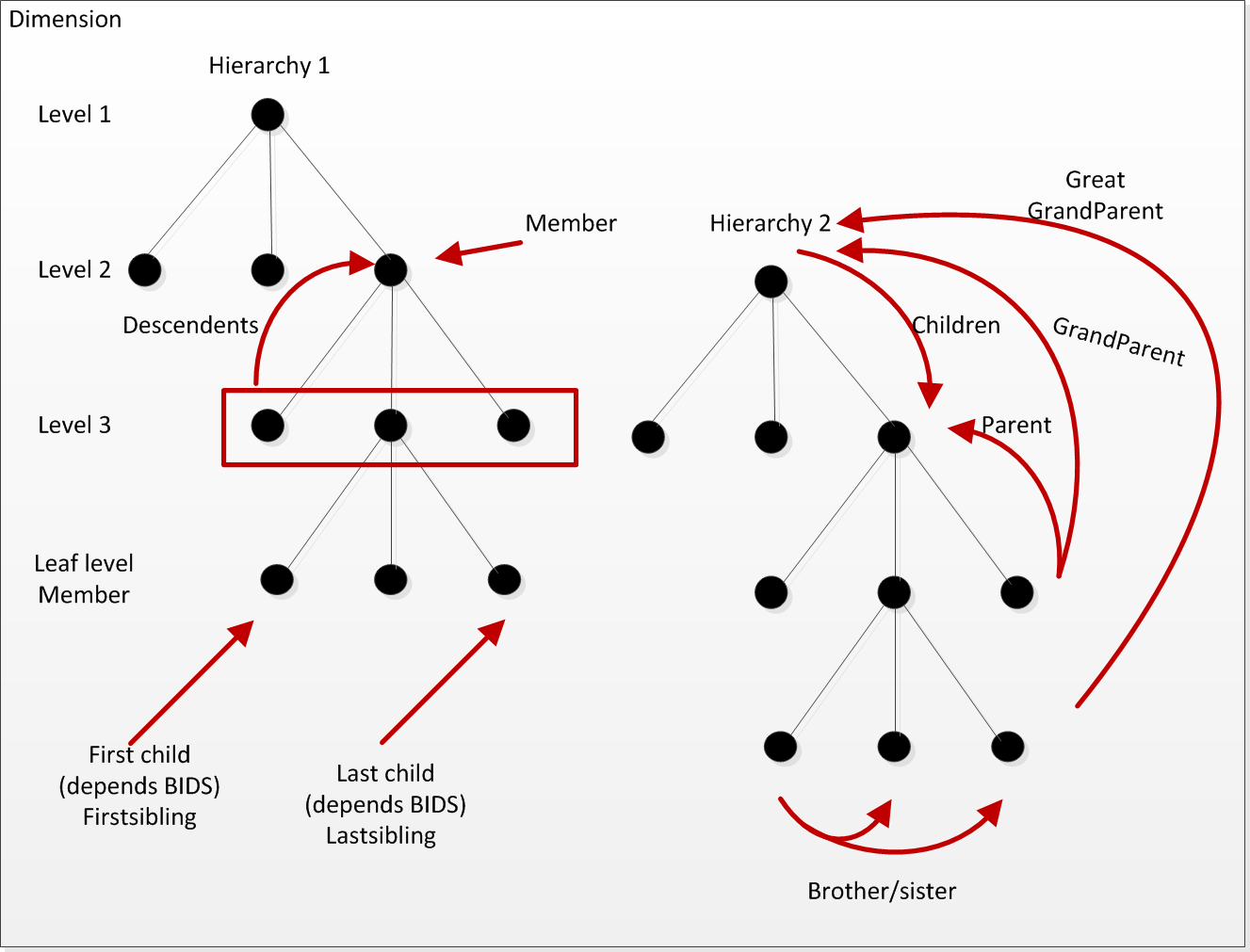
SELECT [Date].[Calendar Year].FirstChild on 0
FROM [Adventure Works];
--Defaultmember
SELECT [Date].[Calendar Year].defaultmember on 0
FROM [Adventure Works];
--
SELECT {([Measures].[Reseller Sales Amount] ,[Date].[Calendar Year].[CY 2006])
, ([Measures].[Reseller Sales Amount],[Date].[Calendar Year].[CY 2007])
}.Item(1) ON COLUMNS
FROM [Adventure Works];
SELECT {([Measures].[Reseller Sales Amount] ,[Date].[Calendar Year].[CY 2006])
, ([Measures].[Reseller Sales Amount],[Date].[Calendar Year].[CY 2007])
} ON COLUMNS
FROM [Adventure Works];
SELECT {[Calendar Quarter].[Q1 CY 2005]:[Calendar Quarter].[Q4 CY 2007]} ON 0
FROM [Adventure Works];
SELECT {
[Calendar Quarter].[Q1 CY 2006],
[Calendar Quarter].[Q2 CY 2006],
[Calendar Quarter].[Q3 CY 2006],
[Calendar Quarter].[Q4 CY 2006]
} ON 0
FROM [Adventure Works];
-- Named set
WITH SET [EUROPE] AS '{[Customer].[Country].&[France],
[Customer].[Country].&[Germany],
[Customer].[Country].&[United Kingdom]}'
SELECT Measures.[Internet Sales Amount] ON COLUMNS,
[EUROPE] ON ROWS
FROM [Adventure Works];
--Named Set and Set operators
WITH SET [EUROPE] AS '{[Customer].[Country].&[France]} + {[Customer].[Country].&[United Kingdom]}'
SELECT Measures.[Internet Sales Amount] ON COLUMNS,
[EUROPE] ON ROWS
FROM [Adventure Works];
--Named Set and Set operators
WITH SET [EUROPE] AS '{[Customer].[Country].&[France]} + {[Customer].[Country].&[United Kingdom]}'
SELECT Measures.[Internet Sales Amount] ON COLUMNS,
[EUROPE] ON ROWS
FROM [Adventure Works];
--Named Set and Set operators (Cross Product)
WITH SET [EUROPE] AS '{[Customer].[Country].&[France], [Customer].[Country].&[United Kingdom]} *
{[Product].[Product Line].&[M],[Product].[Product Line].&[R]}'
SELECT Measures.[Internet Sales Amount] ON COLUMNS,
[EUROPE] ON ROWS
FROM [Adventure Works];
-- Calculated members
WITH MEMBER Measures.[profit] AS [Measures].[Internet Sales Amount] - [Measures].[Internet Standard Product Cost]
SELECT measures.profit ON COLUMNS,
[Customer].[Country].MEMBERS ON ROWS
FROM [Adventure Works];
with member [Measures].[PCT Discount] AS '[Measures].[Discount Amount]/[Measures].[Reseller Sales Amount]', FORMAT_STRING = 'Percent'
set Top10SellingProducts as 'topcount([Product].[Model Name].children, 10, [Measures].[Reseller Sales Amount])'
//set Preferred10Products as '
//{[Product].[Model Name].&[Mountain-200],
//[Product].[Model Name].&[Road-250],
//[Product].[Model Name].&[Mountain-100],
//[Product].[Model Name].&[Road-650],
//[Product].[Model Name].&[Touring-1000],
//[Product].[Model Name].&[Road-550-W],
//[Product].[Model Name].&[Road-350-W],
//[Product].[Model Name].&[HL Mountain Frame],
//[Product].[Model Name].&[Road-150],
//[Product].[Model Name].&[Touring-3000]
//}'
select {[Measures].[Reseller Sales Amount], [Measures].[Discount Amount], [Measures].[PCT Discount]} on 0,
Top10SellingProducts on 1
from [Adventure Works];
-- Combined named set and calculated set.
-- order products based on the internet Sales Amount and returns the sales amount of each product along with the rank.
WITH
SET [Product Order] AS 'Order([Product].[Product Line].MEMBERS, [Internet Sales Amount], BDESC)'
MEMBER [Measures].[Product Rank] AS 'RANK([Product].[Product Line].CURRENTMEMBER, [Product Order])'
SELECT {[Product Rank], [Sales Amount]} ON COLUMNS,
[Product Order] ON ROWS
FROM [Adventure Works];
--each half year is analyzed along with the cumulative sales for the whole year
WITH MEMBER Measures.[Cumulative Sales] AS 'Sum(YTD(), [Internet Sales Amount])'
SELECT {Measures.[Internet Sales Amount], Measures.[Cumulative Sales]} ON 0,
[Date].[Calendar].[Calendar Semester].MEMBERS ON 1
FROM [Adventure Works];
--each month is analyzed along with the cumulative sales for the whole year
WITH MEMBER Measures.[Cumulative Sales] AS 'Sum(YTD(), [Internet Sales Amount])'
SELECT {Measures.[Internet Sales Amount], Measures.[Cumulative Sales]} ON 0,
[Date].[Calendar].[Month].MEMBERS ON 1
FROM [Adventure Works];
--9,061,000.58
SELECT [Measures].[Internet Sales Amount] ON COLUMNS
FROM [Adventure Works]
WHERE [Customer].[Country].[Australia];
--$11,038,845.45
SELECT [Measures].[Internet Sales Amount] ON COLUMNS
FROM [Adventure Works]
WHERE {[Customer].[Country].[Australia],
[Customer].[Country].[Canada]};
--$9,770,899.74
SELECT [Measures].[Internet Sales Amount] ON COLUMNS
FROM [Adventure Works]
WHERE [Date].[Calendar Year].&[2008];
--
SELECT
{ [Measures].[Sales Amount], [Measures].[Tax Amount] } ON COLUMNS,
{ [Date].[Fiscal].[Fiscal Year].&[2007], [Date].[Fiscal].[Fiscal Year].&[2008] } ON ROWS
FROM [Adventure Works]
WHERE ( [Sales Territory].[Southwest] );
SELECT CROSSJOIN({[Date].[Calendar Year].ALLMEMBERS},{[Measures].[Internet Sales Amount]})
FROM [Adventure Works];
-- Crossjoin, Allmembers (normale dim?), Children (igv een hierarchie?)
SELECT
CROSSJOIN({[Date].[Calendar Year].ALLMEMBERS},{[Measures].[Internet Sales Amount]}) ON AXIS (0),
{[Product].[Product Categories].CHILDREN} ON AXIS (1)
FROM [Adventure Works];
-- : = Range operator
SELECT CROSSJOIN({[Measures].ALLMEMBERS}, {[Date].[Calendar Year].[CY 2005]: [Date].[Calendar Year].[CY 2008]}) ON AXIS (0),
CROSSJOIN({[Product].[Product Categories].CHILDREN},[Customer].[Country].[Country].MEMBERS) ON AXIS (1)
FROM [Adventure Works];
--MDX Functions
WITH MEMBER measures.LocationName AS [Customer].[Country].CurrentMember.Name
SELECT measures.LocationName ON COLUMNS,
Customer.Country.members on ROWS
FROM [Adventure Works];
WITH MEMBER measures.User AS USERNAME
SELECT measures.User ON 0
FROM [Adventure Works];
--SET Functions
SELECT Measures.[Internet Sales Amount] ON COLUMNS,
FILTER(CROSSJOIN({Product.[Product Line].[Product Line].MEMBERS},
{[Customer].[Country].Members}), [Internet Sales Amount] >200000) ON ROWS
FROM [Adventure Works];
--Memberfunction (ParallelPeriod)
SELECT ParallelPeriod ([Date].[Calendar].[Calendar Quarter]
, 3
, [Date].[Calendar].[Month].[October 2007])
ON 0
FROM [Adventure Works];
SELECT ParallelPeriod ([Date].[Calendar].[Calendar Quarter]
, 1
, [Date].[Calendar].[Month].[November 2007])
ON 0
FROM [Adventure Works];
Bye bye,
Hennie































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}