We encountered an interesting problem at our project. By accident all the objects in the database were deleted. It was a development database and all our code was in Git. We lost only some testdata. Something strange happened with the way we (tried to) recovered from the problem. What we did was the following:
And we thought we were ok. Problem solved. Not! The constraints were gone.
Let me show you what happened.
First, let's investigate what happened. The following experiment is a simulation about happened :
Resulting in a table with a value for id.
The experiment start with the following statements and this will result in an error.
//=============================================================================
// Experiment
//============================================================================
-- WAIT 10 seconds
select * from Test at(offset => -10);
DROP TABLE IF EXISTS Test;
select * from Test at(offset => -60);
It results in an error because the table doesn't exists anymore. I assume that the constraints are gone too in the metadata of Snowflake. Now, the next step is to create a clone of the database before the deletion of the table. Wait for a moment (a couple of minutes or so) in order to have clone the database easily.
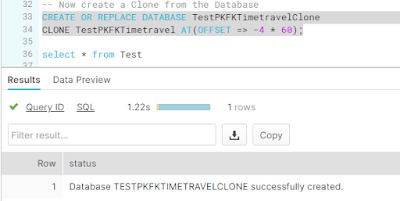
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone
CLONE TestPKFKTimetravel AT(OFFSET => -4 * 60);
This results in a clone of the database before the deletion of the table (and timing is essential here ;-)).
Ok, let's query the table and see whether we have the data back.
USE DATABASE TestPKFKTimetravelClone;
select * from Test;
Resulting in the following information according to the folowing screendump :
Wow, that looks great! We have our table and our data back. But now comes the caveat. The constraints are gone!
SELECT GET_DDL('Table', 'Test')
Results in :
And here is the output of GET_DDL() statement :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL
);
Conclusion 1
The constraint is gone! Why does this happen? Well, from the documentation about constraints of Snowflake I read the following : "For Snowflake Time Travel, when previous versions of a table are copied, the current version of the constraints on the table are used because Snowflake does not store previous versions of constraints in table metadata.". Although here is stated that it is applicable on tables, it seems applicable on databases clones too. That is interesting! So when you want to timetravel with a table (or database) you need to be aware of changing constraints. So you can't be compliant when you want to time travel over a database. You need to be aware what the state of the constraint was at the moment of the time travel.
Let's experiment a bit more with timetravelling and constraints to learn more about this 'feature'.
Experiment 2 : Change the constraint and travel back in time
What will happen when the constraint is changed and you use time travel functionality of Snowflake? Let's experiment with this. First setup the database.
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
CREATE OR REPLACE DATABASE TestPKFKTimetravel2;
USE DATABASE TestPKFKTimetravel2;
CREATE OR REPLACE TABLE Test (
id integer,
name varchar,
PRIMARY KEY (id));
INSERT INTO Test(id, name) VALUES(1, 'Hennie');
select * from Test;
SELECT GET_DDL('Table', 'Test');
And, the GET_DDL() statement results in the following DDL script for the table Test :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
A primary key on the ID kolom.
Now let's change the PK on the table from the column 'id' to 'name'.
ALTER TABLE Test DROP PRIMARY KEY;
ALTER TABLE Test ADD PRIMARY KEY (name);
SELECT GET_DDL('Table', 'Test');
And check the DDL again to make sure that the PK has changed from ID to name.
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (NAME)
);
Let's clone the database again from before the change of the constraint. Offcourse timing is essential here.
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone2
CLONE TestPKFKTimetravel2 AT(OFFSET => - 3 * 60);
Let's go back to the clone and see what GET_DDL() is giving back as a result:
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216)
);
NO PK! This seems to be in contrast with the statement of Snowflake : "For Snowflake Time Travel, when previous versions of a table are copied, the current version of the constraints on the table are used because Snowflake does not store previous versions of constraints in table metadata.".
Conclusion 2
This is also something I didn't expect from the experiment. It seems that when you time travel and clone no constraint is applied(?!). The constraint seems to be gone.
Experiment 3 : Just go back in time, clone and check the constraint
The previous experiment does me wonder whether the constraint is properly stored in the metadata for timetravelling. Just to make sure whether this is working correclty is set up this experiment with time travelling with Snowflake.
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
CREATE OR REPLACE DATABASE TestPKFKTimetravel3;
USE DATABASE TestPKFKTimetravel3;
CREATE OR REPLACE TABLE Test (
id integer,
name varchar,
PRIMARY KEY (id));
INSERT INTO Test(id, name) VALUES(1, 'Hennie');
select * from Test;
SELECT GET_DDL('Table', 'Test');
And as expected we have a correct DDL of the table.
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
Okay, now let's time travel and see whether the PK is still present in the clone.
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone3
CLONE TestPKFKTimetravel3 AT(OFFSET => - 60);
USE DATABASE TestPKFKTimetravelClone3;
select * from Test;
SELECT GET_DDL('Table', 'Test')
This is the result of the GET_DDL() statement.
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
And here we have the constraint. It is still here.
Conclusion 3
When nothing changes with constraints of a table during time, timetravel will return the right constraint back.
Experiment 4 : Just clone and see what happens with the constraints
Just to make sure whether clones works correctly, I setup the following experiment with a clone of a database, change the constraints and see if they don't interfere with each other. Just to make sure whether it works as expected.
We setup another experiment with a database, we create a table with a PK and query the DDL with GET_DDL().
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
--Setup the base database
CREATE OR REPLACE DATABASE TestPKFKTimetravel4;
USE DATABASE TestPKFKTimetravel4;
CREATE OR REPLACE TABLE Test (
id integer,
name varchar,
PRIMARY KEY (id));
INSERT INTO Test(id, name) VALUES(1, 'Hennie');
SELECT GET_DDL('Table', 'Test')
This results in a database with a table with a constraint. The GET_DDL() statement gives the following result :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
PK is on the ID column the table Test.
The next step is to create a clone of the database and check the DDL of the table.
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone4 CLONE TestPKFKTimetravel4;
USE DATABASE TestPKFKTimetravelClone4;
select * from Test;
SELECT GET_DDL('Table', 'Test');
And this results in the same DDL as expected :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
Now change the DDL in the original database.
USE DATABASE TestPKFKTimetravel4;
ALTER TABLE Test DROP PRIMARY KEY;
ALTER TABLE Test ADD PRIMARY KEY (name);
SELECT GET_DDL('Table', 'Test')
And this results in the following DDL code :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (NAME)
);
So, the PK in the original database is on NAME and the PK in the clone database is on ID. Let's find out whether this is still true.
USE DATABASE TestPKFKTimetravelClone4;
SELECT GET_DDL('Table', 'Test')
Resulting in :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
Yes, so this is still true. The primary key in the original database is 'id' and in the clone database is based on 'name'.
Now, lets go back to original database and drop the table.
USE DATABASE TestPKFKTimetravel4;
DROP TABLE test;
SELECT GET_DDL('Table', 'Test')
The table doesn'exist anymore.
SQL compilation error: Table 'TEST' does not exist or not authorized.
And then go back to the clone and see what the status is in the clone:
USE DATABASE TestPKFKTimetravelClone4;
select * from Test;
SELECT GET_DDL('Table', 'Test')
Resulting in the following DDL :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
The primary key on the table is still based on the column 'id'. Next step is to replace the original database with the clone.
DROP DATABASE IF EXISTS TestPKFKTimetravel4;
ALTER DATABASE IF EXISTS TestPKFKTimetravelClone4 RENAME TO TestPKFKTimetravel4;
USE DATABASE TestPKFKTimetravel4;
select * from Test;
SELECT GET_DDL('Table', 'Test')
Results in :
create or replace TABLE TEST (
ID NUMBER(38,0) NOT NULL,
NAME VARCHAR(16777216),
primary key (ID)
);
And now we have the table back as we original started with.
Conclusion 4
We cloned the database, we changed the constraints in the original database, and we restored the clone back to the original database and the PK is back on track. This seems to work all as expected. The metadata of the constraints is separated between the original and the clone database.
Final thoughts
The experience we had with timetravel and constraints made us wonder about the inner workings of timetravel, cloning and constraints. We were a bit surprised with the lack of constraints when we cloned a databased from an earlier time with time travel. And still, it seems that when something changes with the constraints you can't rely on the table structure anymore. Only cloning seems to be reliable to go back time if you create a clone every day. Time travel doesn't seem to be a good alternative for differential backup/incremental backup and restore.
The whole script.
//=============================================================================
// Set context
//============================================================================
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
//=============================================================================
// Experiment 2 : Drop the table and time travel back to before the drop.
//============================================================================
CREATE OR REPLACE DATABASE TestPKFKTimetravel;
CREATE OR REPLACE TABLE Test (
id integer,
PRIMARY KEY (id));
INSERT INTO Test(id) VALUES(1);
-- WAIT 10 seconds
select * from Test at(offset => -10);
DROP TABLE IF EXISTS Test;
select * from Test at(offset => -60);
-- Now create a clone from the Database
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone
CLONE TestPKFKTimetravel AT(OFFSET => -4 * 60);
USE DATABASE TestPKFKTimetravelClone;
select * from Test;
SELECT GET_DDL('Table', 'Test');
ALTER WAREHOUSE IF EXISTS COMPUTE_WH SUSPEND;
//=============================================================================
// Experiment 2 : Change the PK from id to name and travel back in time
//=============================================================================
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
CREATE OR REPLACE DATABASE TestPKFKTimetravel2;
USE DATABASE TestPKFKTimetravel2;
CREATE OR REPLACE TABLE Test (
id integer,
name varchar,
PRIMARY KEY (id));
INSERT INTO Test(id, name) VALUES(1, 'Hennie');
select * from Test;
SELECT GET_DDL('Table', 'Test');
-- Change the Primary Key to name
ALTER TABLE Test DROP PRIMARY KEY;
ALTER TABLE Test ADD PRIMARY KEY (name);
SELECT GET_DDL('Table', 'Test');
--DROP TABLE IF EXISTS Test;
select * from Test at(offset => -60);
-- Now create a clone from the Database
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone2
CLONE TestPKFKTimetravel2 AT(OFFSET => - 3 * 60);
USE DATABASE TestPKFKTimetravelClone2;
select * from Test;
SELECT GET_DDL('Table', 'Test')
ALTER WAREHOUSE IF EXISTS COMPUTE_WH SUSPEND;
//=============================================================================
// Experiment 3 : Just go back in time, clone and check the constraint
//=============================================================================
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
CREATE OR REPLACE DATABASE TestPKFKTimetravel3;
USE DATABASE TestPKFKTimetravel3;
CREATE OR REPLACE TABLE Test (
id integer,
name varchar,
PRIMARY KEY (id));
INSERT INTO Test(id, name) VALUES(1, 'Hennie');
select * from Test;
SELECT GET_DDL('Table', 'Test');
select * from Test at(offset => -60);
-- Now create a clone from the Database
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone3
CLONE TestPKFKTimetravel3 AT(OFFSET => - 60);
USE DATABASE TestPKFKTimetravelClone3;
select * from Test;
SELECT GET_DDL('Table', 'Test')
ALTER WAREHOUSE IF EXISTS COMPUTE_WH SUSPEND;
//=============================================================================
// Experiment 4 : Just clone and see what happens with the constraints
//=============================================================================
ALTER WAREHOUSE IF EXISTS COMPUTE_WH RESUME IF SUSPENDED;
USE ROLE SYSADMIN;
USE WAREHOUSE Compute_WH;
--Setup the base database
CREATE OR REPLACE DATABASE TestPKFKTimetravel4;
USE DATABASE TestPKFKTimetravel4;
CREATE OR REPLACE TABLE Test (
id integer,
name varchar,
PRIMARY KEY (id));
INSERT INTO Test(id, name) VALUES(1, 'Hennie');
SELECT GET_DDL('Table', 'Test')
//-- Change the Primary Key to name
//ALTER TABLE Test DROP PRIMARY KEY;
//ALTER TABLE Test ADD PRIMARY KEY (name);
//SELECT GET_DDL('Table', 'Test')
-- Now create a clone from the Database
CREATE OR REPLACE DATABASE TestPKFKTimetravelClone4 CLONE TestPKFKTimetravel4;
USE DATABASE TestPKFKTimetravelClone4;
select * from Test;
SELECT GET_DDL('Table', 'Test');
-- Change the the PK of the original database
USE DATABASE TestPKFKTimetravel4;
ALTER TABLE Test DROP PRIMARY KEY;
ALTER TABLE Test ADD PRIMARY KEY (name);
SELECT GET_DDL('Table', 'Test')
-- Look at the clone and verify the contraints
USE DATABASE TestPKFKTimetravelClone4;
SELECT GET_DDL('Table', 'Test')
--Let's go back to the base database and drop the table
USE DATABASE TestPKFKTimetravel4;
DROP TABLE test;
SELECT GET_DDL('Table', 'Test')
-- Look at the clone and verify the contraints
USE DATABASE TestPKFKTimetravelClone4;
select * from Test;
SELECT GET_DDL('Table', 'Test')
DROP DATABASE IF EXISTS TestPKFKTimetravel4;
ALTER DATABASE IF EXISTS TestPKFKTimetravelClone4 RENAME TO TestPKFKTimetravel4;
USE DATABASE TestPKFKTimetravel4;
select * from Test;
SELECT GET_DDL('Table', 'Test')
--Shutdown the warehouse
ALTER WAREHOUSE IF EXISTS COMPUTE_WH SUSPEND;