In many of my projects i've done sofar, i had to combine tables in order to retrieve keys for my fact tables. When there is a perfect relation available, no worries, no problem. If this perfect relation is perfectly modelled then linking and retrieving proper keys is much more easier then when there is a relation that is not based on proper relation modelling. Sometimes there are cases when you need to link sources from different departments that do not have a common primary-foreign key. Sometimes you need to link tables based on some descriptive fields that are used in both tables. The second problem is that when you do have some fields available for 'fuzzy linking', they return multiple rows back. Returning multiple rows back can cause wrong counts in your fact table. Therefore you need to align the counts of the "default fact source table" with the 'referenced table'.
For this post i've developed a small example in such a way that it represents the problem i want to examine. In the diagram below the order table is the table that is used as a source for the fact table and i need the department from the order log table to incorporate this in the (to be build) fact table.The relation is based on ''fuzzy linkage" : customer code and a date. And, i need the department key in my fact table. The problem is that there are (for the same customer and date) multiple records with different departments. Therefore a simple distinct won't work.

In the past i've solved this with a double subqueries and this is not a good solution because the performance is bad. I decided to investigate this problem in more dept in this post. In this post i'll discover the different options that are available to solve this problem.
I've four queries developed and these are investigated in this blog.
- Option 1 : double subquery.
- Option 2 : joining with subquery.
- Option 3 : CTE solution.
- Option 4 : OUTER APPLY solution.
The case
This is the script i've used for analyzing the queries:
USE [FuzzyLinking]
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[tblOrder]') AND type in (N'U'))
DROP TABLE [dbo].[tblOrder]
GO
CREATE TABLE [dbo].[tblOrder](
[OrderID] [int] IDENTITY(1,1) NOT NULL,
[OrderDate] [Datetime] NOT NULL,
[CustomerCode] [varchar] (10) NOT NULL,
[Amount] [int] NOT NULL
) ON [PRIMARY]
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[tblOrderLog]') AND type in (N'U'))
DROP TABLE [dbo].[tblOrderLog]
GO
CREATE TABLE [dbo].[tblOrderLog](
[OrderLogID] [int] IDENTITY(1,1) NOT NULL,
[OrderLogDate] [datetime] NOT NULL,
[CustomerCode] [varchar] (10) NOT NULL,
[DepartmentCode] [int] NOT NULL
) ON [PRIMARY]
GO
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[tblDepartment]') AND type in (N'U'))
DROP TABLE [dbo].[tblDepartment]
GO
CREATE TABLE [dbo].[tblDepartment](
[DepartmentCode] [int] NOT NULL,
[DepartmentDescription] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
---
INSERT INTO dbo.tblDepartment ( DepartmentCode, DepartmentDescription)
VALUES
(1, 'Department A'),
(2, 'Department B'),
(3, 'Department C'),
(4, 'Department D'),
(5, 'Department E')
INSERT INTO [dbo].[tblOrder] ([OrderDate],[CustomerCode],[Amount])
VALUES
('2011-08-15 19:40:14.163', 'A', 20.95),
('2011-08-15 05:40:14.554', 'B', 99.54),
('2011-08-16 18:35:25.143', 'B', 12.55),
('2011-08-17 17:23:11.123', 'C', 15.00),
('2011-08-18 23:12:18.434', 'A', 25.00),
('2011-08-19 17:34:12.345', 'A', 27.00);
INSERT INTO [dbo].[tblOrderLog] ([OrderLogDate],[CustomerCode],[DepartmentCode])
VALUES ('2011-08-15 20:40:14.163', 'A', 1),
('2011-08-15 22:12:11.163', 'A', 2),
('2011-08-15 05:55:14.554', 'B', 2),
('2011-08-16 19:35:25.143', 'C', 3),
('2011-08-17 18:23:11.123', 'C', 3),
('2011-08-19 00:12:18.434', 'A', 2),
('2011-08-19 18:12:18.434', 'A', 3),
('2011-08-19 18:12:18.434', 'A', 4),
('2011-08-20 00:12:18.434', 'A', 5);Analysis
When i write a simple join between the Order and Orderlogtable based on 'customercode' and 'day'
{kind=link}
SELECT
O.OrderID,
O.OrderDate,
O.CustomerCode,
OL.OrderLogID,
OL.OrderLogDate,
OL.DepartmentCode
FROM tblOrder O
INNER JOIN tblOrderLog OL ON O.CustomerCode = OL.CustomerCode
AND CONVERT(varchar(8),O.[OrderDate], 112) = CONVERT(varchar(8),OL.[OrderLogDate], 112) this is resulting in :
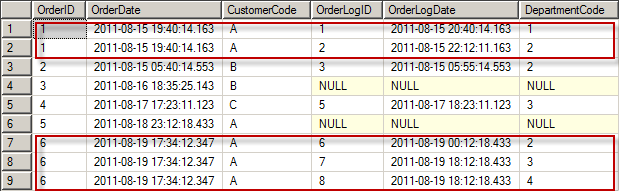
As you can see we have multiple OrderID's and this is not a good situation for using this in a fact table. Instead of 6 fact records we now have 9 records and this is caused by the cartesian poduct. This is not a good base for a fact table. So we need some additional work here.
The queries
Option 1
Okay, the first solution here is the one i've used in some of my projects (i've to admit) and that is this query:
SELECT
O.OrderID,
O.OrderDate,
O.CustomerCode,
D.DepartmentCode
FROM tblOrder O
LEFT OUTER JOIN (
SELECT OrderLogDate, CustomerCode, DepartmentCode
FROM tblOrderLog
WHERE OrderLogID IN
(SELECT Min(OrderLogID)
FROM tblOrderLog
GROUP BY CONVERT(varchar(8),[OrderLogDate], 112) , CustomerCode)) D ON CONVERT(varchar(8),O.[OrderDate], 112) = CONVERT(varchar(8),D.[OrderLogDate], 112)
AND O.CustomerCode= D.CustomerCodeand this returns :

And this is ok. Now i've 6 orders back again. I choosed to take the first orderlog record and the related department. This depends on the businessrules, off course.
I'm not very satisfied with this solution because two subqueries doesn't seem a good (and a fast) solution to me.
Option 2
Another option i've researched is the query below. In this query i've reduced the subqueries to one.
SELECT
O.OrderID,
O.OrderDate,
O.CustomerCode,
OL.DepartmentCode
FROM tblOrder O
LEFT OUTER JOIN tblOrderLog OL ON OL.OrderLogID =
(SELECT TOP 1 OrderLogID
FROM tblOrderLog OL1
WHERE CONVERT(varchar(8),O.[OrderDate], 112) = CONVERT(varchar(8),OL1.[OrderLogDate], 112)
AND O.CustomerCode= OL1.CustomerCode
ORDER BY O.CustomerCode, CONVERT(varchar(8),OL1.[OrderLogDate], 112))And this returns the same values as the query in option 1:

Option 3
Yet another option i've found is the query written down below. In this query the subsubquery is now vanished. Instead we have now a Common Table Expression (CTE) used.
WITH CTE_order AS
(SELECT
O.OrderID,
O.OrderDate,
O.CustomerCode,
OL.DepartmentCode,
ROW_NUMBER() OVER (PARTITION BY O.OrderID ORDER BY O.OrderDate) AS RowNo
FROM tblOrder O
LEFT OUTER JOIN tblOrderLog OL ON CONVERT(varchar(8),O.[OrderDate], 112) = CONVERT(varchar(8),OL.[OrderLogDate], 112)
AND O.CustomerCode = OL.CustomerCode)
SELECT
OrderID,
OrderDate,
CustomerCode,
DepartmentCode
FROM CTE_order
WHERE RowNo = 1 OR OrderDate IS NULL;Also resulting in the same results as we've seen before.
Option 4
In the next option i'm using an OUTER APPLY. The OUTER APPLY operator is used for combining tables when there is not a direct JOIN ON possible and you need to join tables based on some fields that are not keys, like in this case. So this seems a perfect match, solving this problem with the OUTER APPLY. This is the query:
SELECT
O.OrderID,
O.OrderDate,
O.CustomerCode,
O1.DepartmentCode
FROM tblOrder O
OUTER APPLY
(
SELECT TOP 1 OrderLogID, DepartmentCode
FROM tblOrderLog OL1
WHERE CONVERT(varchar(8),O.[OrderDate], 112) = CONVERT(varchar(8),OL1.[OrderLogDate], 112)
AND O.CustomerCode= OL1.CustomerCode
ORDER BY O.CustomerCode, CONVERT(varchar(8),OL1.[OrderLogDate], 112)
) O1 Resulting in.....Yep the same as before :
Comparing the queries
As i've read about the OUTER APPLY it has a better performance than subqueries or other solutions. Is this really true? Let's find out. I took the four queries and included the actual query plan and compared the costs. Studying the actual execution plan indicates that the OUTER APPLY is best option (of the four). As i already assumed the double subquery is a bad performer.

Conclusion
I've compared 4 options regarding this specific problem. The problem was about (what i call) 'fuzzy linking' between two tables and retrieving an appropriate key for the fact table. Below you can see the results in a graph and as i already thought : the double subquery is worst option (option 1) and the best solution (of the 4) is option 4 (the OUTER APPLY):

I've learned a bit more about SQL Server and the OUTER APPLY. I do think that i'll be using this feature more often in tasks like joining tables based on some not key fields.
Greetz,
Hennie
Geen opmerkingen:
Een reactie posten