Introduction
Today, I want to write something about Fact based Oriented Modelling (FOM). FOM is not about modeling objects in the real world but it is focused on modeling the communication about the objects in the world around us. This is another focus than methods like Codd or Chen. During projects, I gathered information about the area of interest and one of the next steps was trying to imagine the objects and model the data. For instance, you have Patient data and you define the Patient entity. This approach is different than FOM. With FOM you gather the information from communication and verbalize the information in so called fact expressions.
Semantics
I've noticed that during discussions I've had so far, semantics is a much used keyword. Although I was aware of a kind of meaning of this word, I decided to google it, and here is what I found:
"The branch of linguistics and logic concerned with meaning. The two main areas are logical semantics, concerned with matters such as sense and reference and presupposition and implication, and lexical semantics, concerned with the analysis of word meanings and relations between them."
In my opinion, this is saying that semantics is the area of understanding the meaning of communication between (business)people. As a data modeler it is important to understand the wording, the meaning and the relations between the (certain) words.
Verbalization
Fact expressions are important in FOM. FOM expressions are based on predicate logic. They are true or not. For instance you can say something like: "There is a student called Peter Janssen" or "Order 12345 is ordered on February 15th, 2019". The first one is a so called postulated existent expression (I hope I translated that from Dutch correctly) and the latter one is elementary fact expression, meaning it is the minimal information to identify the fact. In other words, there is no redundant information and there is not to less information.
For this blogpost, I've used the following examples (translated from Dutch) from the book Fully Communication Oriented Information Modeling (FCO-IM) by G.Bakema, J. Zwart and H. van der Lek. This is a very readable book about FOM.
English version here.
There is a student Peter Jansen.
There is a student Jan Hendriks.
Student Peter Jansen lives in Nijmegen.
Student Jan Hendriks lives in Nijmegen.
Internship S101 is available.
Internship S102 is available.
Student Peter Jansen prefers nr 1 stage S101.
Student Peter Jansen prefers nr 2 stage S203.
Stage S101 takes place in Nijmegen.
Stage S102 takes place in Eindhoven.
Stage S101 is developing a time registration program.
Stage S102 is researching CASE tooling.
Student Peter Jansen is assigned to internship S101.
Student Jan Hendriks is assigned to internship S203.
As you can see, these sentences are easier to verify by business users than a Bachman- or a Chen diagram. Users can say: "No that is not correct, it should be this or that". So this is the first, but very important step in data modeling with FOM. I've not seen this kind of approach earlier. You can say that is the conceptual level of modelling! It models the facts in the communication.
Qualification and Classification
When you are satisfied with the verbalizing the facts, the next step starts. That is grouping the fact expressions into categories and giving the group a name. This is called qualification and classification. For instance, sentences like "There is a student Peter jansen" and "There is a student Jan Hendriks" are grouped together and named "Student".
[Student]
There is a student Peter Jansen.
There is a student Jan Hendriks.
[Residence]
Student Peter Jansen lives in Nijmegen.
Student Jan Hendriks lives in Nijmegen.
[Internship]
Internship S101 is available.
Internship S102 is available.
[Internshippreference]
Student Peter Jansen prefers nr 1 stage S101.
Student Peter Jansen prefers nr 2 stage S203.
[Internshiplocation]
Stage S101 takes place in Nijmegen.
Stage S102 takes place in Eindhoven.
[Internshipdescription]
Stage S101 is developing a time registration program.
Stage S102 is researching CASE tooling.
[internshipassignment]
Student Peter Jansen is assigned to internship S101.
Student Jan Hendriks is assigned to internship S203.
Creating an Information Grammatical Diagram (IGD)
When verbalization is done the next step is executed: designing an IGD. This model is not used for communication with end users because the diagram can be overwhelming and difficult to understand by novice users. IT people prefer abstract diagrams to understand the area of interest better.
Now, you can do it manually or you can use a tool like
CaseTalk. Let's take the first fact expression and try to identify the labels and objects here. Objects are things that we want to know more about it. Objects should have an unique identification. Labels are descriptive information.
Below, I have used CaseTalk to identify the labels firstname and lastname. On the right an impression of the diagram is shown. FactType Student has two roles with two labels firstname and lastname.
This results in the following part of an IGD. A fact expression with placeholders 1 and 2 that can instantiated by "Peter Jansen" and "Jan Hendriks". I've entered the second sentence into CaseTalk too.
The next step is to enter all of the sentences aka fact expressions into CaseTalk. For instance, when the next fact expression is entered, the diagram is changed into the following :
Now we can derive two fact expressions from this model : There is a Student Jan Hendriks and Student Peter Jansen lives in Nijmegen.
When all of the Fact expressions are entered in CaseTalk the diagram appears as follows:
In this diagram all of the Fact types are added and the Factexpressions can be derived from the model. For instance,
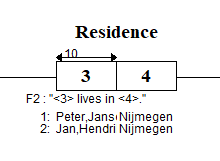
F2 : <3> lives in <4>.
Role 3 is played by the nominalized objecttype Student which is Student <1><2>.
Role 1 is played by labeltype first name and role 2 is played by labeltype last name.
Role 4 is played by Nominalized objecttype Place <5>.
Role 5 is played by the labeltype placename.
Now this result in the following substitution:
"Student Jan Hendriks lives in Nijmegen"
Final thoughts
This is a short description about Fact Oriented Modelling. I've explained verbalization, classification and qualification, deriving an IGD from fact expressions. In the next blogpost, I'll focus on the constraints of a model. Although there is a structure in the model, there are more limitations/constraints possible, for instance there can be only one student with the same name. This will be subject for the following blogpost.
Hennie



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}