Introduction
In this blogpost, I've written a description about the models I've created sofar based on the AdventureWorks LT database in Snowflake. In the previous blogpost I described the setup of the project and I created a Customer model. In this blogpost I'll create the other views (models) on the AdventureWorksLT Database.
This blogpost is a blogpost in a serie of blogposts :
Creating the staging models
I've already created the Staging Customer model in the previous blogpost.
stg_Customer
WITH CTE_STG_CUSTOMER AS (
SELECT *
FROM ADVENTUREWORKSLT.SALESLT.CUSTOMER
)
SELECT
SUFFIX
,MIDDLENAME
,EMAILADDRESS
,COMPANYNAME
,NAMESTYLE
,PASSWORDHASH
,CUSTOMERID
,PHONE
,SALESPERSON
,TITLE
,FIRSTNAME
,LASTNAME
,MODIFIEDDATE
,ROWGUID
,PASSWORDSALT
FROM CTE_STG_CUSTOMER;
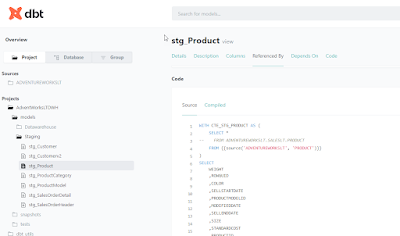
stg_Product
WITH CTE_STG_PRODUCT AS (
SELECT *
FROM ADVENTUREWORKSLT.SALESLT.PRODUCT
)
SELECT
WEIGHT
,ROWGUID
,COLOR
,SELLSTARTDATE
,PRODUCTMODELID
,MODIFIEDDATE
,SELLENDDATE
,SIZE
,STANDARDCOST
,PRODUCTID
,LISTPRICE
,THUMBNAILPHOTOFILENAME
,THUMBNAILPHOTO
,NAME
,PRODUCTNUMBER
,DISCONTINUEDDATE
,PRODUCTCATEGORYID
FROM CTE_STG_PRODUCT
stg_ProductCategory
WITH CTE_STG_PRODUCTCATEGORY AS (
SELECT *
FROM ADVENTUREWORKSLT.SALESLT.PRODUCTCATEGORY
)
SELECT
PARENTPRODUCTCATEGORYID
,MODIFIEDDATE
,PRODUCTCATEGORYID
,ROWGUID
,NAME
FROM CTE_STG_PRODUCTCATEGORY
stg_ProductModel
WITH CTE_STG_PRODUCTMODEL AS (
SELECT *
FROM ADVENTUREWORKSLT.SALESLT.PRODUCTMODEL
)
SELECT
ROWGUID
,CATALOGDESCRIPTION
,PRODUCTMODELID
,NAME
,MODIFIEDDATE
FROM CTE_STG_PRODUCTMODEL
stg_SalesOrderDetail
This view is the base for the fact Sales.
WITH CTE_STG_SALESORDERDETAIL AS (
SELECT *
FROM ADVENTUREWORKSLT.SALESLT.SALESORDERDETAIL
)
SELECT
PRODUCTID
,ORDERQTY
,ROWGUID
,MODIFIEDDATE
,LINETOTAL
,UNITPRICEDISCOUNT
,UNITPRICE
,SALESORDERDETAILID
,SALESORDERID
FROM CTE_STG_SALESORDERDETAIL
stg_SalesOrderHeader
This view is the base for the fact Sales.
WITH CTE_STG_SALESORDERHEADER AS (
SELECT *
FROM ADVENTUREWORKSLT.SALESLT.SALESORDERHEADER
)
SELECT
FREIGHT
,SALESORDERID
,REVISIONNUMBER
,COMMENT
,ROWGUID
,MODIFIEDDATE
,STATUS
,ORDERDATE
,SHIPTOADDRESSID
,BILLTOADDRESSID
,CREDITCARDAPPROVALCODE
,SHIPDATE
,SUBTOTAL
,TAXAMT
,CUSTOMERID
,PURCHASEORDERNUMBER
,TOTALDUE
,ACCOUNTNUMBER
,DUEDATE
,SHIPMETHOD
,ONLINEORDERFLAG
FROM CTE_STG_SALESORDERHEADER
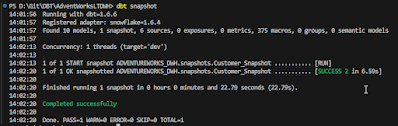
DBT RUN
Okay, We setup the project in Visual Studio Code and now the next step is to run the model to make sure that the objects are created in the Data warehouse.
And when dbt run is run the following views are created in Snowflake :
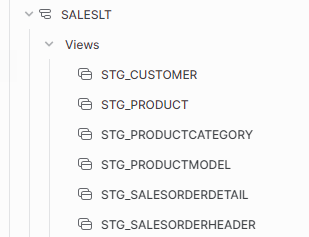
Dimensions
Th next step is to create the data warehouse in Snowflake with DBT:
Dim_Calendar
I've copied the code from my earlier blogpost about creating a date dimension with the GENERATOR function. Now, I had to comment the first line because DBT returns an error when I execute the script. I haven't searched for an solution, yet.
--ALTER SESSION SET WEEK_START = 7
WITH CTE_MY_DATE AS (
SELECT DATEADD(DAY, SEQ4(), '2000-01-01') AS MY_DATE
FROM TABLE (GENERATOR(ROWCOUNT => 365 * 40 + 10))
)
SELECT
TO_NUMBER(TO_CHAR(MY_DATE,'yyyymmdd')) AS CalendarID
,TO_DATE(MY_DATE) AS CalendarShortDate
,TO_DATE(MY_DATE) - 1 AS CalendarPreviousDate
,TO_DATE(MY_DATE) + 1 AS CalendarNextDate
,TO_VARCHAR(MY_DATE, 'DD/MM/YYYY') AS CalendarShortDateStyle103
,TO_VARCHAR(MY_DATE, 'DD-MM-YYYY') AS CalendarShortDateStyle105
,TO_VARCHAR(MY_DATE, 'MM-DD-YYYY') AS CalendarShortDateStyle110
,TO_VARCHAR(MY_DATE, 'MM/DD/YYYY') AS CalendarShortDateStyle101
,CASE WHEN DATE_PART(day, MY_DATE) / 10 = 1 THEN 'th' ELSE
CASE RIGHT(DATE_PART(day, MY_DATE), 1)
WHEN '1' THEN 'st'
WHEN '2' THEN 'nd'
WHEN '3' THEN 'rd'
ELSE 'th' END
END AS CalendarDaySuffix
,DATE_PART(dayofweek, MY_DATE) AS CalendarDayOfWeek
,DATE_PART(dayofweekiso, MY_DATE) AS CalendarDayOfWeekISO
,DATE_PART(day, MY_DATE) AS CalendarDayOfMonth
,DATE_PART(dayofyear, MY_DATE) AS CalendarDayOfYear
,DAYNAME(MY_DATE) AS CalendarShortDayName
,DECODE(DAYNAME(MY_DATE),
'Mon','Monday',
'Tue','Tuesday',
'Wed', 'Wednesday',
'Thu','Thursday',
'Fri', 'Friday',
'Sat','Saturday',
'Sun', 'Sunday'
) AS CalendarLongDayName
, CASE WHEN DATE_PART(dayofweekiso, MY_DATE) NOT IN (6,7) THEN 1 ELSE 0 END AS CalendarIsWeekDay
, CASE WHEN DATE_PART(dayofweekiso, MY_DATE) IN (6,7) THEN 1 ELSE 0 END AS CalendarIsWeekendDay
, DATEADD(day, -1 * (DATE_PART(DAYOFWEEK, MY_DATE) -1), MY_DATE) AS WeekStartDate --Sunday
, DATEADD(day, -1 * (DATE_PART(DAYOFWEEKISO, MY_DATE) -1), MY_DATE) AS WeekStartISODate --Monday
, DATEADD(day, 6 - (DATE_PART(DAYOFWEEK, MY_DATE)-1), MY_DATE) AS WeekEndDate --Sunday
, DATEADD(day, 6 - (DATE_PART(DAYOFWEEKISO, MY_DATE) -1), MY_DATE) AS WeekEndISODate --Monday
, TO_DATE(DATEADD(day, - (DATE_PART(day, MY_DATE) - 1), MY_DATE)) AS CalendarFirstDayOfMonth
, LAST_DAY(MY_DATE, 'month') AS CalendarLastDayOfMonth
, TO_DATE(DATEADD(quarter, DATEDIFF(quarter, '2000-01-01'::TIMESTAMP, MY_DATE), '2000-01-01'::TIMESTAMP)) AS CalendarFirstDayOfQuarter
, LAST_DAY(MY_DATE, 'quarter') AS CalendarLastDayOfQuarter
, TO_DATE('01/01/' || TO_VARCHAR(DATE_PART(year, MY_DATE))) AS CalendarFirstDayOfYear
, LAST_DAY(MY_DATE, 'year') AS CalendarLastDayOfYear
-- Week
, DATE_PART(week, MY_DATE) AS CalendarWeekOfYear
, RIGHT('0' || DATE_PART(week, MY_DATE), 2) || YEAR(DATEADD(day, 26 - DATE_PART(week, MY_DATE), MY_DATE)) AS CalendarWWYYYY
, YEAR(DATEADD(day, 26 - DATE_PART(week, MY_DATE), MY_DATE)) || RIGHT('0' || DATE_PART(week, MY_DATE), 2) AS CalendarYYYYWW
, CASE WHEN DATE_PART(week, CalendarLastDayOfYear) = 53 THEN 1 ELSE 0 END AS Has53Weeks
-- WeekISO
, DATE_PART(weekiso, MY_DATE) AS CalendarISOWeekOfYear
, RIGHT('0' || DATE_PART(weekiso, MY_DATE), 2) || YEAR(DATEADD(day, 26 - DATE_PART(weekiso, MY_DATE), MY_DATE)) AS CalendarISOWWYYYY
, YEAR(DATEADD(day, 26 - DATE_PART(weekiso, MY_DATE), MY_DATE)) || RIGHT('0' || DATE_PART(weekiso, MY_DATE), 2) AS CalendarISOYYYYWW
, CASE WHEN DATE_PART(weekiso, CalendarLastDayOfYear) = 53 THEN 1 ELSE 0 END AS Has53ISOWeeks
-- Month
, DATE_PART(month, MY_DATE) AS CalendarMonthNumber
, CASE WHEN CalendarISOWeekOfYear >= 1 AND CalendarISOWeekOfYear <= 4 Then 1 --4
WHEN CalendarISOWeekOfYear >= 5 AND CalendarISOWeekOfYear <= 8 Then 2 --4
WHEN CalendarISOWeekOfYear >= 9 AND CalendarISOWeekOfYear <= 13 Then 3 --5
WHEN CalendarISOWeekOfYear >= 14 AND CalendarISOWeekOfYear <= 17 Then 4 --4
WHEN CalendarISOWeekOfYear >= 18 AND CalendarISOWeekOfYear <= 21 Then 5 --4
WHEN CalendarISOWeekOfYear >= 22 AND CalendarISOWeekOfYear <= 27 Then 6 --5
WHEN CalendarISOWeekOfYear >= 28 AND CalendarISOWeekOfYear <= 31 Then 7 --4
WHEN CalendarISOWeekOfYear >= 32 AND CalendarISOWeekOfYear <= 35 Then 8 --4
WHEN CalendarISOWeekOfYear >= 36 AND CalendarISOWeekOfYear <= 40 Then 9 --5
WHEN CalendarISOWeekOfYear >= 41 AND CalendarISOWeekOfYear <= 44 Then 10 --4
WHEN CalendarISOWeekOfYear >= 45 AND CalendarISOWeekOfYear <= 48 Then 11 --4
WHEN CalendarISOWeekOfYear >= 49 AND CalendarISOWeekOfYear <= 53 Then 12 --5
END AS CalendarISOMonthNumber
, TO_VARCHAR(DATE_PART(year, MY_DATE)) || RIGHT('0' || TO_VARCHAR(DATE_PART(month, MY_DATE)),2) AS CalendarYYYYMM
, RIGHT('0' || TO_VARCHAR(DATE_PART(month, MY_DATE)),2) || TO_VARCHAR(DATE_PART(year, MY_DATE)) AS CalendarMMYYYY
, CASE WHEN DATE_PART(weekiso, LAST_DAY(MY_DATE, 'year')) = 53 THEN 1 ELSE 0 END AS CalendarHas53ISOWeeks
-- Quarter
, DATE_PART(quarter, MY_DATE) AS CalendarQuarter
, CASE WHEN CalendarISOWeekOfYear >= 1 AND CalendarISOWeekOfYear <= 13 Then 1
WHEN CalendarISOWeekOfYear >= 14 AND CalendarISOWeekOfYear <= 27 Then 2
WHEN CalendarISOWeekOfYear >= 28 AND CalendarISOWeekOfYear <= 40 Then 3
WHEN CalendarISOWeekOfYear >= 41 AND CalendarISOWeekOfYear <= 53 Then 4
END AS CalendarISOQuarter
-- Year
, DATE_PART(year, MY_DATE) AS CalendarYear
, 'CY ' || TO_VARCHAR(CalendarYear) AS CalendarYearName
-- , YEAR(DATEADD(day, 26 - DATE_PART(weekiso, MY_DATE), MY_DATE)) AS CalendarISOYear
,DATE_PART(yearofweekiso, MY_DATE) AS CalendarISOYear
, CASE WHEN (CalendarYear % 400 = 0) OR (CalendarYear % 4 = 0 AND CalendarYear % 100 <> 0)
THEN 1
ELSE 0
END AS CalendarIsLeapYear
FROM CTE_MY_DATE
Dim_Customer
One of the cool things about DBT is the ref function. With the ref function you can reference models in your project.
WITH CTE_DIM_CUSTOMER AS (
SELECT *
FROM {{ref('stg_Customer')}}
)
SELECT
SUFFIX
,MIDDLENAME
,EMAILADDRESS
,COMPANYNAME
,NAMESTYLE
,PASSWORDHASH
,CUSTOMERID
,PHONE
,SALESPERSON
,TITLE
,FIRSTNAME
,LASTNAME
,MODIFIEDDATE
,ROWGUID
,PASSWORDSALT
FROM CTE_DIM_CUSTOMER
Dim_Product
The product dimension :
WITH CTE_STG_PRODUCT AS (
SELECT *
FROM {{ref('stg_Product')}}
),
CTE_STG_PRODUCTCATEGORY AS (
SELECT *
FROM {{ref('stg_ProductCategory')}}
),
CTE_STG_PRODUCTMODEL AS (
SELECT *
FROM {{ref('stg_ProductModel')}}
)
SELECT
P.PRODUCTID
,P.PRODUCTNUMBER
,P.NAME AS PRODUCTNAME
,P.SELLSTARTDATE
,P.SELLENDDATE
,P.DISCONTINUEDDATE
,P.COLOR
,P.SIZE
,P.WEIGHT
,P.STANDARDCOST
,P.LISTPRICE
,PC.NAME AS PRODUCTCATEGORY
,PM.NAME AS PRODUCTMODEL
FROM CTE_STG_PRODUCT P
INNER JOIN CTE_STG_PRODUCTCATEGORY PC ON P.PRODUCTCATEGORYID = PC.PRODUCTCATEGORYID
INNER JOIN CTE_STG_PRODUCTMODEL PM ON P.PRODUCTMODELID = PM.PRODUCTMODELID
Fact_Sales
And the Fact Sales Fact..
WITH CTE_stg_SalesOrderHeader AS (
SELECT *
FROM SALESLT.stg_SalesOrderHeader
),
CTE_stg_SalesOrderDetail AS (
SELECT *
FROM SALESLT.stg_SalesOrderdetail
)
SELECT
SOH.CUSTOMERID --FK dimension
,SOD.PRODUCTID --FK dimension
,SOH.SALESORDERID --DD
,SOH.PURCHASEORDERNUMBER
,SOH.ACCOUNTNUMBER
,SOH.REVISIONNUMBER
,SOH.COMMENT
,SOH.SHIPMETHOD
,SOH.ONLINEORDERFLAG
,TO_NUMBER(TO_CHAR(SOH.ORDERDATE,'yyyymmdd')) AS ORDERDATEID --FK Calendar dimension
,SOH.MODIFIEDDATE
,TO_NUMBER(TO_CHAR(SOH.SHIPDATE,'yyyymmdd')) AS SHIPDATEID
,TO_NUMBER(TO_CHAR(SOH.DUEDATE,'yyyymmdd')) AS DUEDATEID
,SOH.STATUS
,SOH.CREDITCARDAPPROVALCODE
,SOH.FREIGHT
,SOD.LINETOTAL
,SOD.UNITPRICEDISCOUNT
,SOD.UNITPRICE
,SOD.SALESORDERDETAILID
FROM CTE_stg_SalesOrderHeader SOH
INNER JOIN CTE_stg_SalesOrderDetail SOD ON SOH.SALESORDERID = SOD.SALESORDERID
And when the scripts are done, lets run dbt run :
And now lets check if all the objects are created in Snowflake
Materialize dim and fact as a table
But, do we want for every object and view? May be it's logical to use a view for lightweight transformations, but for the query intensive objects like dimensions and facts it might logical to use tables. In DBT we can change that in the dbt_project.yml file. Use thename of the folder to distinguish the staging views from the dimension and fact tables.
Let's run dbt run and check the presence of views and tables in Snowflake :
Yes that worked pretty well.
Final Thoughts
In this blogpost I've created a small data warehouse with DBT. I'll continue with blogging about DBT in the next blogposts.
Hennie